

Next: References
Independent Component Analysis,
Blind Source Separation, and
Projection Pursuit
Aapo Hyvärinen
Helsinki University of Technology
Laboratory of Computer and Information Science
P.O. Box 2200, FIN-02015 HUT, Finland
aapo.hyvarinen@hut.fi
http://www.cis.hut.fi/~ aapo/
Slides presented at the EC Summer School on Bayesian Signal Processing
Cambridge, UK, 24 July 1998
Independent Component Analysis.
Observed (zero-mean) random vector 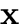 is modelled by a linear latent variable model [31,11]:
is modelled by a linear latent variable model [31,11]:
|
 |
(1) |
where
-
The 'mixing' matrix
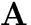 is constant, usually square.
is constant, usually square.
-
Latent variables si are mutually independent and nongaussian.
-
Estimate both
and
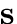 ,
observing only .
,
observing only .
-
The si defined only up to a multiplicative constant.
-
The si are not ordered.
Whitening (or decorrelation) of
is not enough to estimate the model [31]:

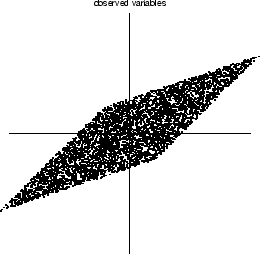

-
whitening gives
only up to an orthogonal transformation.
-
Whitening uses only correlation matrix:
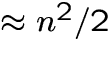 equations, but
has n2 elements.
equations, but
has n2 elements.
-
After whitening,
can be considered orthogonal.
-
Therefore, model cannot be estimated for gaussian data!
-
Higher-order information enables estimation of model [31,11].
Cf. edges in above density.
Basic intuitive principle.
(Sloppy version of) the Central Limit Theorem [8,14,13,20].
-
Consider a linear combination
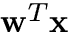 .
.
-
ai si+aj sj
is more gaussian than si.
-
Maximizing the nongaussianity of ,
we can find si.
-
Also known as projection pursuit.
-
Problem: how to measure nongaussianity?
Measures of nongaussianity.
(normalize x to unit variance)
1. Absolute value of kurtosis (fourth-order cumulant) [14,20,13]
|
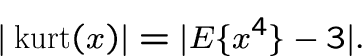 |
(2) |
Simple algebraic properties, but sensitive to outliers.
2. Differential entropy [11,14,20]:
|
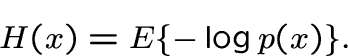 |
(3) |
Good statistical properties, but computationally difficult.
3. Approximations of entropy [23]
|
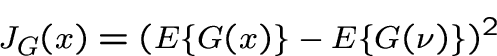 |
(4) |
where 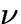 is gaussian, and G a suitable function.
is gaussian, and G a suitable function.
-
statistical properties not bad (for suitable G)
-
computationally simple
-
a good compromise?
4. Other measures (for the record):
-
other than 4th-order cumulants (skewness) [14,20]
-
Fisher information
![$E\{ [(\log p)'(x)]^2 \}$](img14.gif) .
[20]
.
[20]
-
L2 distances [18,12]
Illustration.
For whitened data, maximize e.g. 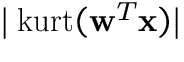 ,
with
,
with 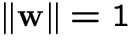 :
:
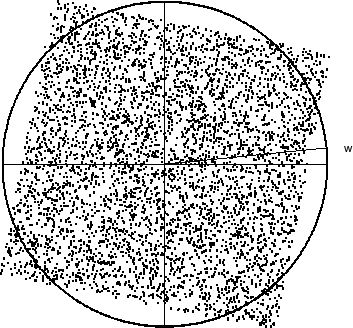
Whitened data.
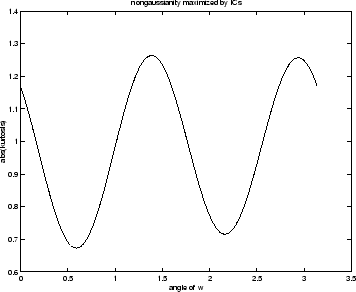
Modulus of kurtosis as a function of angle. Maxima are obtained
in the directions of the independent components.
To estimate several ICs, use the constraint of decorrelation [13,28].
Maximum likelihood estimation.
-
Log-likelihood of the model: (
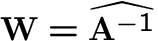 )
[43,7,8]
)
[43,7,8]
|
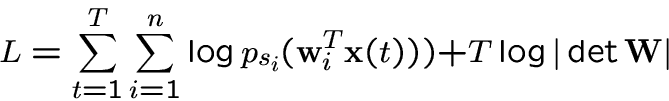 |
(5) |
-
Equivalent to the infomax approach in neural networks [5,7,38].
-
Needs estimates of the psi, but these need not be exact
at all [9,8].
-
If estimates constrained to be white, essentially equivalent to above one-by-one
estimation (for differential entropy and its approximations).
-
MAP estimation: Jeffreys' prior [42]
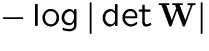 does not change much.
does not change much.
Information-theoretic approach.
-
Mutual information of n random variables
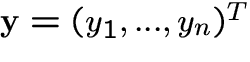 [8,11]:
[8,11]:
|
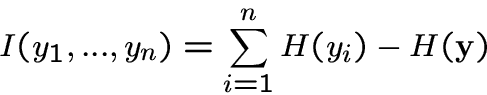 |
(6) |
where H is differential entropy.
-
A measure of redundancy of
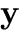 .
Equals zero iff yi are independent.
.
Equals zero iff yi are independent.
-
For
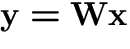 ,
we obtain
,
we obtain
|
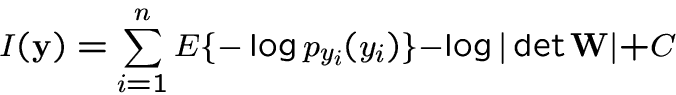 |
(7) |
-
Very similar to likelihood!
Summary of ICA estimation principles.
-
Most approaches differ little.
-
All approaches can be interpreted as maximizing the nongaussianity of ICs.
-
Basic choice: the nonquadratic ('contrast') function in the nongaussianity
measure:
-
kurtosis: fourth power
-
log of density
-
robust alternatives (in approx. of entropy) [21,22].
-
One-by-one estimation vs. estimation of the whole model.
-
Estimates constrained to be white vs. no constraint
Algorithms (1). Adaptive gradient methods
-
Gradient methods for one-by-one estimation straightforward [13,27,29,22].
-
Stochastic gradient ascent for likelihood [5,43]:
|
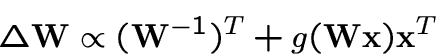 |
(8) |
with 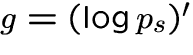 .
Problem: needs matrix inversion!
.
Problem: needs matrix inversion!
-
Better: natural/relative gradient ascent of likelihood [1,2,9,8,10]:
|
![\begin{displaymath}\Delta{\bf W}\propto [{\bf I}+g({\bf y}) {\bf y}^T]{\bf W}\end{displaymath}](img29.gif) |
(9) |
with 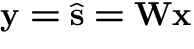 .Obtained
by multiplying gradient by
.Obtained
by multiplying gradient by  .
.
Algorithms (2). Fixed-point algorithm [16,21,28]
-
An approximate Newton method in block (batch) mode.
-
No matrix inversion, but still quadratic (or cubic) convergence.
-
No parameters to be tuned.
-
For a single IC (whitened data)
|
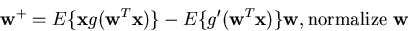 |
(10) |
where g is the derivative of the contrast function.
-
For likelihood:
|
![\begin{displaymath}{\bf W}^+={\bf W}+{\bf D}_1[{\bf D}_2+E\{g({\bf y}) {\bf y}^T\}]{\bf W},\mbox{orthonormalize } {\bf W}\end{displaymath}](img33.gif) |
(11) |
-
The FastICA MATLAB package on the WWW [16].
Relations to other methods.
-
Source separation by decorrelation [6,45]:
-
nongaussianity not used as additional information
-
time-delayed correlations used instead
-
in contrast to ICA, assumes that data is time signals with spectral properties
-
Projection pursuit [20,17]
-
useful for visualization, exploratory data analysis
-
equivalent to one-by-one ICA estimation
-
Factor analysis [19,34]:
ICA is a nongaussian (usually noise-free) version
-
Blind deconvolution [14,44]:
obtained by constraining the mixing matrix
-
Principal component analysis [30]
-
often the same applications
-
very different statistical principles
Extensions of basic ICA model.
1. Noisy ICA: 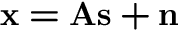
-
EM algorithm [37]:
computationally complex
-
cumulant-based algorithms [35]:
statistically problematic
-
bias reduction techniques [15,25]:
perhaps most promising
2. More observations than independent components
-
simple solution (?): reduce dimension by PCA [31]
3. Less observations than independent components
-
ML algorithms still possible [41,36]
-
quite complicated
Applications (1). Blind source separation
Four ICs ('source signals'):
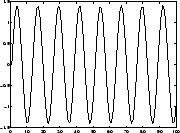
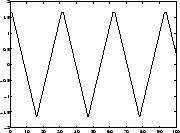
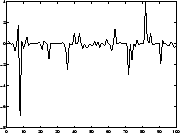
Due to some external circumstances, only linear mixtures of the
source signals are observed.
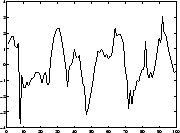
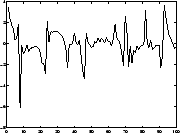
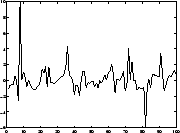
Problem: Estimate (separate) original signals from mixtures!
- Applications: biomedical signals [46,47,48],
telecommunications, audio noise cancelling (cocktail-party problem).
Applications (2). Feature extraction.
-
Barlow's theory of sparse coding, redundancy reduction [3].
-
ICA on image windows gives Gabor/wavelet-like filters:
localized both in space and in frequency [4,32,40]
.
-
nongaussianity of features useful e.g. for denoising [26].
Applications (3). Misc.
-
exploratory data analysis (cf. factor analysis, projection pursuit) [20,17]
-
visualization (like projection pursuit) [20,17]
-
regression [24]
Conclusions.
-
ICA is very simple as a model:
linear nongaussian latent variables model.
-
Estimation not so simple due to nongaussianity:
objective functions cannot be quadratic.
-
Estimation by maximizing nongaussianity of independent components.
-
Algorithms: adaptive (natural gradient descent) vs. block/batch mode (fixed-point).
-
Classical application: blind source separation.
-
Promising applications on feature extraction.
Next: References
Aapo Hyvarinen
8/27/1998