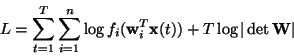A very popular approach for estimating the ICA model is maximum likelihood estimation, which is closely connected to the infomax principle. Here we discuss this approach, and show that it is essentially equivalent to minimization of mutual information.
It is possible to formulate directly the likelihood in the noise-free
ICA model, which was done in [38], and then estimate the
model by a maximum likelihood method.
Denoting by
![]() the matrix
the matrix
![]() ,
the
log-likelihood takes the form [38]:
,
the
log-likelihood takes the form [38]: