The classical measure of nongaussianity is kurtosis or the
fourth-order cumulant.
The kurtosis of y is classically defined by
| (13) |
Kurtosis can be both positive or negative.
Random variables that have a negative kurtosis are called subgaussian,
and those with positive kurtosis are called supergaussian. In
statistical literature, the corresponding expressions platykurtic and
leptokurtic are also used.
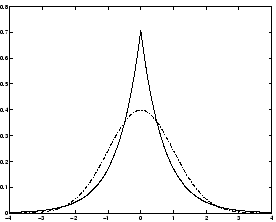
Supergaussian random variables have
typically a ``spiky'' pdf with heavy tails, i.e. the pdf is relatively large at
zero and at large values of the variable, while being small for
intermediate values. A typical example is the Laplace distribution,
whose pdf (normalized to unit variance) is given by
| (14) |
 |
Typically nongaussianity is measured by the absolute value of kurtosis. The square of kurtosis can also be used. These are zero for a gaussian variable, and greater than zero for most nongaussian random variables. There are nongaussian random variables that have zero kurtosis, but they can be considered as very rare.
Kurtosis, or rather its absolute value, has been widely used as a
measure of nongaussianity in ICA and related fields.
The main reason is its simplicity, both computational and
theoretical. Computationally, kurtosis can be estimated simply by
using the fourth moment of the sample data.
Theoretical analysis is simplified because of the following linearity
property:
If x1 and x2 are two independent
random variables, it holds
| (15) |
| (16) |
To illustrate in a simple example what the optimization landscape for
kurtosis looks like, and how independent components could be found by
kurtosis minimization or maximization, let us look at a 2-dimensional
model
![]() .
Assume that the independent components s1, s2have kurtosis values
.
Assume that the independent components s1, s2have kurtosis values
![]() ,
respectively, both
different from zero. Remember that we assumed that they have unit
variances. We seek for one of the independent components as
,
respectively, both
different from zero. Remember that we assumed that they have unit
variances. We seek for one of the independent components as
![]() .
.
Let us again make the transformation
![]() .
Then we have
.
Then we have
![]() .
Now, based on the additive
property of kurtosis, we have
.
Now, based on the additive
property of kurtosis, we have
![]() .
On the other hand, we made the
constraint that the variance of y is equal to 1, based on the same
assumption concerning s1, s2. This implies a constraint on
.
On the other hand, we made the
constraint that the variance of y is equal to 1, based on the same
assumption concerning s1, s2. This implies a constraint on ![]() :
:
![]() .
Geometrically, this means that vector
.
Geometrically, this means that vector
![]() is constrained to the unit circle on the 2-dimensional plane. The
optimization problem is now: what are the maxima of the function
is constrained to the unit circle on the 2-dimensional plane. The
optimization problem is now: what are the maxima of the function
![]() on the unit circle?
For simplicity, you may consider that the kurtosis are of the same
sign, in which case it absolute value operators can be omitted.
The graph of this function is the "optimization landscape" for the
problem.
on the unit circle?
For simplicity, you may consider that the kurtosis are of the same
sign, in which case it absolute value operators can be omitted.
The graph of this function is the "optimization landscape" for the
problem.
It is not hard to show [9] that the maxima are at the
points when exactly
one of the elements of vector ![]() is zero and the other nonzero;
because of the unit circle constraint, the nonzero element must be
equal to 1 or -1. But these points are exactly the ones when yequals one of the independent components
is zero and the other nonzero;
because of the unit circle constraint, the nonzero element must be
equal to 1 or -1. But these points are exactly the ones when yequals one of the independent components ![]() ,
and the problem
has been solved.
,
and the problem
has been solved.
In practice we would start from some weight vector ![]() ,
compute the
direction in which the kurtosis of
,
compute the
direction in which the kurtosis of
![]() is growing most
strongly (if
kurtosis is positive) or decreasing most strongly (if kurtosis is
negative) based on the available sample
is growing most
strongly (if
kurtosis is positive) or decreasing most strongly (if kurtosis is
negative) based on the available sample
![]() of mixture vector
of mixture vector ![]() ,
and use a gradient method or one of
their extensions for finding a new vector
,
and use a gradient method or one of
their extensions for finding a new vector ![]() .
The example can be
generalized to arbitrary dimensions, showing that kurtosis can
theoretically be used as an optimization criterion for the ICA
problem.
.
The example can be
generalized to arbitrary dimensions, showing that kurtosis can
theoretically be used as an optimization criterion for the ICA
problem.
However, kurtosis has also some drawbacks in practice, when its value has to be estimated from a measured sample. The main problem is that kurtosis can be very sensitive to outliers [16]. Its value may depend on only a few observations in the tails of the distribution, which may be erroneous or irrelevant observations. In other words, kurtosis is not a robust measure of nongaussianity.
Thus, other measures of nongaussianity might be better than kurtosis in some situations. Below we shall consider negentropy whose properties are rather opposite to those of kurtosis, and finally introduce approximations of negentropy that more or less combine the good properties of both measures.