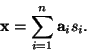To rigorously define ICA [28,7], we can use a
statistical ``latent variables'' model.
Assume that we observe n linear mixtures
x1,...,xn of nindependent components
| (1) |
We have now dropped the time index t; in the ICA model, we assume that each mixture xj as well as each independent component sk is a random variable, instead of a proper time signal. The observed values xj(t), e.g., the microphone signals in the cocktail party problem, are then a sample of this random variable. Without loss of generality, we can assume that both the mixture variables and the independent components have zero mean: If this is not true, then the observable variables xi can always be centered by subtracting the sample mean, which makes the model zero-mean.
It is convenient to use vector-matrix notation instead of the sums
like in the previous equation. Let us denote by ![]() the random vector
whose elements are the mixtures
x1, ..., xn, and likewise by
the random vector
whose elements are the mixtures
x1, ..., xn, and likewise by ![]() the random vector with elements
s1, ... , sn. Let us denote by
the random vector with elements
s1, ... , sn. Let us denote by
![]() the matrix with elements aij. Generally, bold lower case
letters indicate vectors and bold upper-case letters denote
matrices. All vectors are understood as column vectors; thus
the matrix with elements aij. Generally, bold lower case
letters indicate vectors and bold upper-case letters denote
matrices. All vectors are understood as column vectors; thus ![]() ,
or the transpose of
,
or the transpose of ![]() ,
is a row vector. Using this vector-matrix
notation, the above mixing model is written as
,
is a row vector. Using this vector-matrix
notation, the above mixing model is written as
Sometimes we need the columns of matrix ![]() ;
denoting them by
;
denoting them by ![]() the model can also be written as
the model can also be written as
The statistical model in Eq. 4 is called independent component
analysis, or ICA model. The ICA model is a generative model, which means
that it describes how the observed data are generated by a process of
mixing the components si. The independent components
are latent variables, meaning that they cannot be directly observed.
Also the mixing matrix is assumed to be unknown.
All we observe is the random vector ![]() ,
and we must estimate both
,
and we must estimate both
![]() and
and ![]() using it. This must be done under as general assumptions
as possible.
using it. This must be done under as general assumptions
as possible.
The starting point for ICA is the very simple assumption that the
components si are statistically independent. Statistical
independence will be rigorously defined in Section 3. It
will be seen below that we must also assume that the independent
component must have nongaussian distributions. However, in the
basic model we do not assume these distributions known (if they
are known, the problem is considerably simplified.) For simplicity, we are
also assuming that the unknown
mixing matrix is square, but this assumption can be sometimes relaxed,
as explained in Section 4.5. Then, after estimating the
matrix ![]() ,
we can compute its inverse, say
,
we can compute its inverse, say ![]() ,
and obtain the
independent component simply by:
,
and obtain the
independent component simply by:
ICA is very closely related to the method called blind source separation (BSS) or blind signal separation. A ``source'' means here an original signal, i.e. independent component, like the speaker in a cocktail party problem. ``Blind'' means that we no very little, if anything, on the mixing matrix, and make little assumptions on the source signals. ICA is one method, perhaps the most widely used, for performing blind source separation.
In many applications, it would be more realistic to assume that there is some noise in the measurements (see e.g. [17,21]), which would mean adding a noise term in the model. For simplicity, we omit any noise terms, since the estimation of the noise-free model is difficult enough in itself, and seems to be sufficient for many applications.