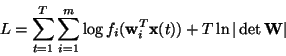It is possible to formulate the likelihood in the noise-free ICA model
(11), which was done in [124], and then estimate the
model by a maximum likelihood method.
Denoting by
![]() the matrix
the matrix
![]() ,
the
log-likelihood takes the form [124]:
,
the
log-likelihood takes the form [124]:
Another related contrast function was derived from a neural network
viewpoint in [12,108]. This was based on maximizing the
output entropy (or information flow) of a neural network with
non-linear outputs. Assume
that ![]() is the input to the neural network whose outputs are of the
form
is the input to the neural network whose outputs are of the
form
![]() ,
where the gi are some non-linear scalar functions, and the
,
where the gi are some non-linear scalar functions, and the ![]() are the weight vectors of the neurons.
One then wants to maximize the entropy of the outputs:
are the weight vectors of the neurons.
One then wants to maximize the entropy of the outputs:
| (14) |
The advantage of the maximum likelihood approach is that under some regularity conditions, it is asymptotically efficient; this is a well-known result in estimation theory [127]. However, there are also some drawbacks. First, this approach requires the knowledge of the probability densities of the independent components. These could also be estimated [124,96], but this complicates the method considerably. A second drawback is that the maximum likelihood solution may be very sensitive to outliers, if the pdf's of the independent components have certain shapes (see [62]), while robustness against outliers is an important property of any estimator [50,56]4.