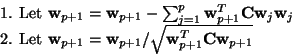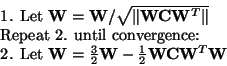The one-unit algorithm of the preceding subsection can be used to
construct a system of n neurons to estimate the whole ICA
transformation using the multi-unit contrast function in (8).
To prevent different neurons from converging to the same maxima
we must decorrelate the outputs
![]() after every iteration.
We present here three methods for achieving this. These methods
do not assume that the data is sphered. If it is, the covariance
matrix
after every iteration.
We present here three methods for achieving this. These methods
do not assume that the data is sphered. If it is, the covariance
matrix ![]() can simply be omitted in the following formulas.
can simply be omitted in the following formulas.
A simple way of achieving decorrelation is a deflation scheme
based on a Gram-Schmidt-like
decorrelation. This means that we estimate the independent components
one by one. When we have estimated p independent components, or p vectors
![]() ,
we run the one-unit fixed-point algorithm for
,
we run the one-unit fixed-point algorithm for
![]() ,
and after every iteration step subtract from
,
and after every iteration step subtract from
![]() the 'projections'
the 'projections'
![]() of the previously estimated
p vectors, and then renormalize
of the previously estimated
p vectors, and then renormalize
![]() :
:
In certain applications, however, it may be desired
to use a symmetric decorrelation, in which
no vectors are 'privileged' over others [28].
This can be accomplished, e.g.,
by the classical method involving matrix
square roots,
Finally, let us note that explicit inversion of the matrix ![]() in
(22) or
(23) can be avoided by using the identity
in
(22) or
(23) can be avoided by using the identity
![]() which is valid for any decorrelating
which is valid for any decorrelating ![]() .
This gives
raise to a fixed-point algorithm in which neither sphering nor inversion of
the covariance matrix is needed. In fact, such an algorithm
can be considered as a fixed-point algorithm for maximum likelihood
estimation of the ICA data model, see [21].
.
This gives
raise to a fixed-point algorithm in which neither sphering nor inversion of
the covariance matrix is needed. In fact, such an algorithm
can be considered as a fixed-point algorithm for maximum likelihood
estimation of the ICA data model, see [21].