To see the connection between likelihood and mutual information,
consider the expectation of the log-likelihood:
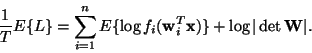 |
(29) |
Actually, in practice the connection is even stronger. This is because
in practice we don't know the distributions of the
independent components. A reasonable approach would be to estimate
the density of
![]() as part of the ML estimation method, and use
this as an approximation of the density of si. In this case,
likelihood and mutual information are, for all practical purposes, equivalent.
as part of the ML estimation method, and use
this as an approximation of the density of si. In this case,
likelihood and mutual information are, for all practical purposes, equivalent.
Nevertheless, there is a small difference that may be very important in practice. The problem with maximum likelihood estimation is that the densities fi must be estimated correctly. They need not be estimated with any great precision: in fact it is enough to estimate whether they are sub- or supergaussian [5,25,31]. In many cases, in fact, we have enough prior knowledge on the independent components, and we don't need to estimate their nature from the data. In any case, if the information on the nature of the independent components is not correct, ML estimation will give completely wrong results. Some care must be taken with ML estimation, therefore. In contrast, using reasonable measures of nongaussianity, this problem does not usually arise.