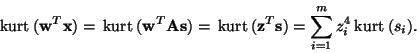Mathematically the simplest one-unit contrast functions are provided
by higher-order cumulants like kurtosis (see Appendix A
for definition).
Denote by ![]() the observed data
vector, assumed to follow the ICA data model (11).
Now, let us search for a linear combination of the observations
xi, say
the observed data
vector, assumed to follow the ICA data model (11).
Now, let us search for a linear combination of the observations
xi, say
![]() ,
such that its kurtosis is maximized or minimized.
Obviously, this optimization problem is meaningful only if
,
such that its kurtosis is maximized or minimized.
Obviously, this optimization problem is meaningful only if
![]() is somehow bounded; let us assume
is somehow bounded; let us assume
![]() .
Using the (unknown)
mixing matrix
.
Using the (unknown)
mixing matrix ![]() ,
let us define
,
let us define
![]() .
Then, using the data model
.
Then, using the data model
![]() one obtains
one obtains
![]() (recall that
(recall that
![]() ), and the well-known properties of kurtosis (see
Appendix A) give
), and the well-known properties of kurtosis (see
Appendix A) give
Kurtosis has been widely used for one-unit ICA (see, for example,
[40,103,71,72]), as well
as for projection pursuit [78].
The mathematical simplicity of the cumulants, and especially
the possibility of proving global convergence results, as in
[40,71,72], has contributed
largely to the popularity of
cumulant-based (one-unit) contrast functions in ICA, projection
pursuit and related fields.
However,
it has been shown, for example in [62], that kurtosis
often provides a rather poor objective function for the estimation of ICA, if
the statistical properties of the resulting estimators are
considered. Note that despite the fact that there is no noise in the
ICA model (11), neither the independent components nor the
mixing matrix can be computed accurately because the independent
components si are random variables, and, in practice, one only has
a finite sample of ![]() .
Therefore, the statistical properties of the
estimators of
.
Therefore, the statistical properties of the
estimators of ![]() and the realizations of
and the realizations of ![]() can be analyzed just
as the properties of any estimator. Such an analysis was conducted in
[62] (see also [28]), and the results show
that in terms of robustness and
asymptotic variance, the cumulant-based estimators tend to be far from
optimal5.
Intuitively, there are two main reasons for this. Firstly,
higher-order cumulants measure mainly the
tails of a distribution, and are largely unaffected by structure in the
middle of the distribution [46].
Secondly, estimators of higher-order cumulants are highly sensitive
to outliers [57].
Their value may depend on only a few observations in the
tails of the distribution, which may be outliers.
can be analyzed just
as the properties of any estimator. Such an analysis was conducted in
[62] (see also [28]), and the results show
that in terms of robustness and
asymptotic variance, the cumulant-based estimators tend to be far from
optimal5.
Intuitively, there are two main reasons for this. Firstly,
higher-order cumulants measure mainly the
tails of a distribution, and are largely unaffected by structure in the
middle of the distribution [46].
Secondly, estimators of higher-order cumulants are highly sensitive
to outliers [57].
Their value may depend on only a few observations in the
tails of the distribution, which may be outliers.